Four Humorous Deepseek Ai News Quotes
페이지 정보

본문
 Nearly all of the 200 engineers authoring the breakthrough R1 paper final month have been educated at Chinese universities, and about half have studied and worked nowhere else. "Nearly all of the 200 engineers authoring the breakthrough R1 paper last month had been educated at Chinese universities, and about half have studied and labored nowhere else. Similar cases have been noticed with different fashions, like Gemini-Pro, which has claimed to be Baidu's Wenxin when requested in Chinese. OpenAI, Google DeepMind, and Anthropic have spent billions training fashions like GPT-4, relying on prime-tier Nvidia GPUs (A100/H100) and massive cloud supercomputers. On HuggingFace, an earlier Qwen mannequin (Qwen2.5-1.5B-Instruct) has been downloaded 26.5M times - extra downloads than standard models like Google’s Gemma and the (historic) GPT-2. For its half, Nvidia-the most important supplier of chips used to prepare AI software-described Free DeepSeek r1’s new model as an "excellent AI advancement" that totally complies with the US government’s restrictions on technology exports.
Nearly all of the 200 engineers authoring the breakthrough R1 paper final month have been educated at Chinese universities, and about half have studied and worked nowhere else. "Nearly all of the 200 engineers authoring the breakthrough R1 paper last month had been educated at Chinese universities, and about half have studied and labored nowhere else. Similar cases have been noticed with different fashions, like Gemini-Pro, which has claimed to be Baidu's Wenxin when requested in Chinese. OpenAI, Google DeepMind, and Anthropic have spent billions training fashions like GPT-4, relying on prime-tier Nvidia GPUs (A100/H100) and massive cloud supercomputers. On HuggingFace, an earlier Qwen mannequin (Qwen2.5-1.5B-Instruct) has been downloaded 26.5M times - extra downloads than standard models like Google’s Gemma and the (historic) GPT-2. For its half, Nvidia-the most important supplier of chips used to prepare AI software-described Free DeepSeek r1’s new model as an "excellent AI advancement" that totally complies with the US government’s restrictions on technology exports.
 One of the chief criticisms of DeepSeek’s new R1 fashions is that they censor solutions that may be opposite to the Chinese government’s policies and speaking factors. Turning small fashions into reasoning models: "To equip more environment friendly smaller models with reasoning capabilities like DeepSeek-R1, DeepSeek we straight high-quality-tuned open-supply fashions like Qwen, and Llama using the 800k samples curated with Free DeepSeek online-R1," DeepSeek write. To this point, the CAC has greenlighted models corresponding to Baichuan and Qianwen, which should not have security protocols as comprehensive as DeepSeek. The exact value of development and energy consumption of DeepSeek aren't absolutely documented, but the startup has introduced figures that counsel its cost was only a fraction of OpenAI’s latest models. The Chinese management, DeepSeek said, have been "instrumental in China’s rapid rise" and in "improving the usual of residing for its citizens". Now comes the backlash: This Chinese upstart? A key debate right now is who ought to be liable for harmful mannequin conduct-the builders who build the fashions or the organizations that use them. DeepSeek had to give you extra environment friendly strategies to prepare its models. Instead of sifting by way of thousands of papers, DeepSeek highlights key research, emerging traits, and cited options.
One of the chief criticisms of DeepSeek’s new R1 fashions is that they censor solutions that may be opposite to the Chinese government’s policies and speaking factors. Turning small fashions into reasoning models: "To equip more environment friendly smaller models with reasoning capabilities like DeepSeek-R1, DeepSeek we straight high-quality-tuned open-supply fashions like Qwen, and Llama using the 800k samples curated with Free DeepSeek online-R1," DeepSeek write. To this point, the CAC has greenlighted models corresponding to Baichuan and Qianwen, which should not have security protocols as comprehensive as DeepSeek. The exact value of development and energy consumption of DeepSeek aren't absolutely documented, but the startup has introduced figures that counsel its cost was only a fraction of OpenAI’s latest models. The Chinese management, DeepSeek said, have been "instrumental in China’s rapid rise" and in "improving the usual of residing for its citizens". Now comes the backlash: This Chinese upstart? A key debate right now is who ought to be liable for harmful mannequin conduct-the builders who build the fashions or the organizations that use them. DeepSeek had to give you extra environment friendly strategies to prepare its models. Instead of sifting by way of thousands of papers, DeepSeek highlights key research, emerging traits, and cited options.
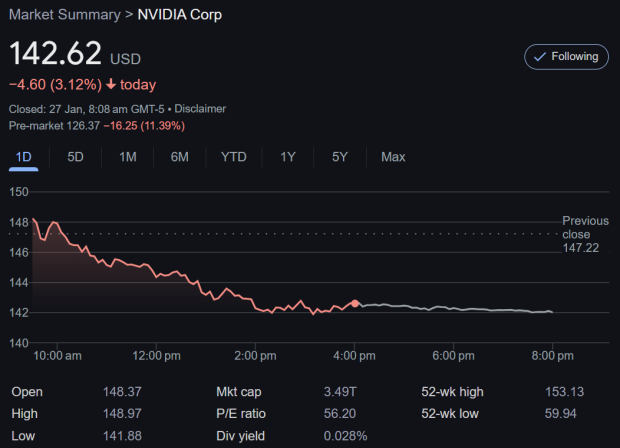
Instead, Agrawal noted that industries equivalent to telecoms will profit from AI by SaaS suppliers, who will enhance their services with extra inexpensive AI options. The function of synthetic clever in promoting sustainability throughout varied industries might be important in mitigating these challenges and guaranteeing a more environmentally pleasant future. As well as to these benchmarks, the model additionally performed nicely in ArenaHard and MT-Bench evaluations, demonstrating its versatility and capability to adapt to varied duties and challenges. On the World Economic Forum in Davos (January 20-24, 2025), some mentioned Hangzhou-based DeepSeek and its recently launched R1 model as a major cause for nations such because the US to be doubling down on synthetic intelligence (AI) developments. Second, DeepSeek didn't copy U.S. The Working Group has additionally been tasked with evaluating the creation of a "strategic nationwide digital property stockpile." While the main points are still imprecise, this initiative could mean that the U.S.
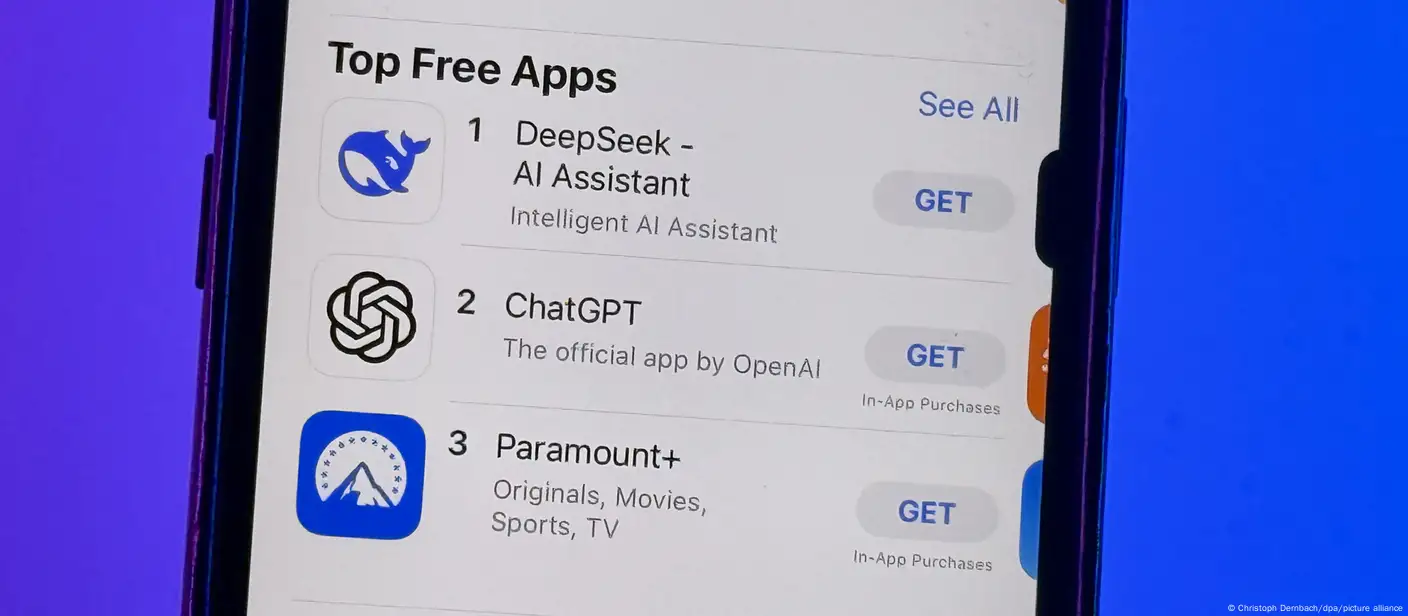
While DeepSeek R1 scored 90.8% in MMLU, ChatGPT-o1 scored 91.8% - a single percent greater than the brand new AI platform. While it is probably not as fast as Claude 3.5 Sonnet, it has potential for duties that require intricate reasoning and problem breakdown. Considered one of the key variations between using Claude 3.5 Opus inside Cursor and instantly by way of the Anthropic API is the context and response dimension. Yes, I couldn't wait to start utilizing responsive measurements, so em and rem was great. The company says the DeepSeek-V3 model cost roughly $5.6 million to train using Nvidia’s H800 chips. Instead, regulatory focus may need to shift towards the downstream penalties of mannequin use - probably putting extra duty on those that deploy the fashions. Scott Wiener and written in close collaboration with the center for AI Safety, has been criticized as making essentially the most highly effective AI fashions difficult or unattainable to launch as open-source. The DeepSeek-R1 launch does noticeably advance the frontier of open-supply LLMs, however, and suggests the impossibility of the U.S. Third, DeepSeek’s announcement roiled U.S. Unlike some rivals, DeepSeek’s assistant reveals its work and reasoning because it addresses a user’s written question or immediate. By the end of the weekend, DeepSeek’s AI assistant had rocketed to the top of Apple Inc.’s iPhone obtain charts and ranked among the highest downloads on Google’s Play Store, straining the startup’s systems a lot that the service went down for greater than an hour.
- 이전글Why You Never See A Adsense Revenue Calculator That Truly Works 25.02.20
- 다음글تحديث واتساب الذهبي القديم الأصلي وتس عمر الذهبي 25.02.20
댓글목록
등록된 댓글이 없습니다.